
LLM-ek valós idejű adat beszerzése
A mesterséges intelligencia térnyerésével együtt azt is meg kell vizsgálni, hogy a SEO hogyan veszíti el lassan a erejét/népszerűségét, és hogyan lépünk be egy új korszakba, amelyet az AI-natív felfedezése (kérdés-felelek)határoz meg.
Több mint két évtizeden át a Google diktálta a szabályokat: írjon be egy kulcsszót, görgessen végig a hivatkozásokon, kattintson néhányra. Ez a modell több mint 200 milliárd dolláros birodalmat épített fel. De ma ez a rendszer egyre elavultabbnak tűnik, vagy inkáb háttérbe szorul.
2024-ben és azt követően a felhasználók főleg a mesterséges intelligencia hatására nem keresnek, hanem kérnek. Legyen szó ChatGPT-ről, Geminiről vagy Perplexityről, az emberek azonnali, kiváló minőségű válaszokat várnak, egyetlen beszélgetésben. Nem akarnak tíz blogbejegyzést végignézni a legjobb választ akarják – MOST.
“A ChatGPT, a Perplexity és a Claude korában a Generative Engine Optimization a márka láthatóságának új játékkönyvévé válik. Nem az algoritmus kijátszásáról van szó, hanem arról, hogy hivatkoznak rá.
A GEO-ban nyerő márkák nem csak az AI-válaszokban jelennek meg. Ők alakítják majd őket.” — a16z .
Akkor most elértünk a bejegyzés témájáhooz, ha az AI-eszközök több kérdésre adnak választ, mint a keresőmotorok, hogyan teszik ezt valós időben?
A változás, amely átformálja a webes keresési viselkedést
Sokan úgy gondolkoznak és már ki is jelentették a SEO idő előtti halálát. Mások teljesen irrelevánsnak tartják, most, hogy egyre több keresés zajlik az LLM felületeken, például a ChatGPT-n belül. Ami azonban valójában a felszín alatt történik, az magának a keresésnek az evolúciója, amely végső soron a felhasználók számára előnyös. Az AI-eszközök egyre inkább előtérbe helyezik a minőséget, a relevanciát, a bizalmat és a tekintélyt a kulcsszavakkal teli blogbejegyzésekkel és a különféle optimalizálási taktikákkal szemben.
Csendes forradalom zajlik az emberek online információkeresésében. Ahelyett, hogy hagyományos keresőmotorokhoz, például a Google-hoz fordulnának, ma már milliók kérik a ChatGPT-t, a Claude-ot, a Perplexityt és más mesterséges intelligencia eszközöket, hogy adjanak nekik közvetlen választ. Ez a változás a felhasználói viselkedést megváltoztatja.
De van egy kulcskérdés, amelyet kevesen tesznek fel: honnan származnak valójában ezek a valós idejű adatok?
Ha az AI-eszközök aktuálisnak, időszerűnek és konkrétnak tűnő válaszokat adnak, hogyan tudják ezt kihozni, ha statikus adatokra tanítják őket?
Szóval, hogyan tudnak az olyan LLM-ek, mint a ChatGPT, a Gemini és a Perplexity valós idejű válaszokat adni a statikus képzés világában? Soroljuk fel a három fő forrást, amelyre támaszkodnak, hogyan működik a folyamat a színfalak mögött, és mit kell tenniük az weboldal tulajdonosoknak, hogy láthatóak maradjanak az AI-vezérelt keresési világban.
1. Keresőmotorok: A valós idejű visszakeresés első sora
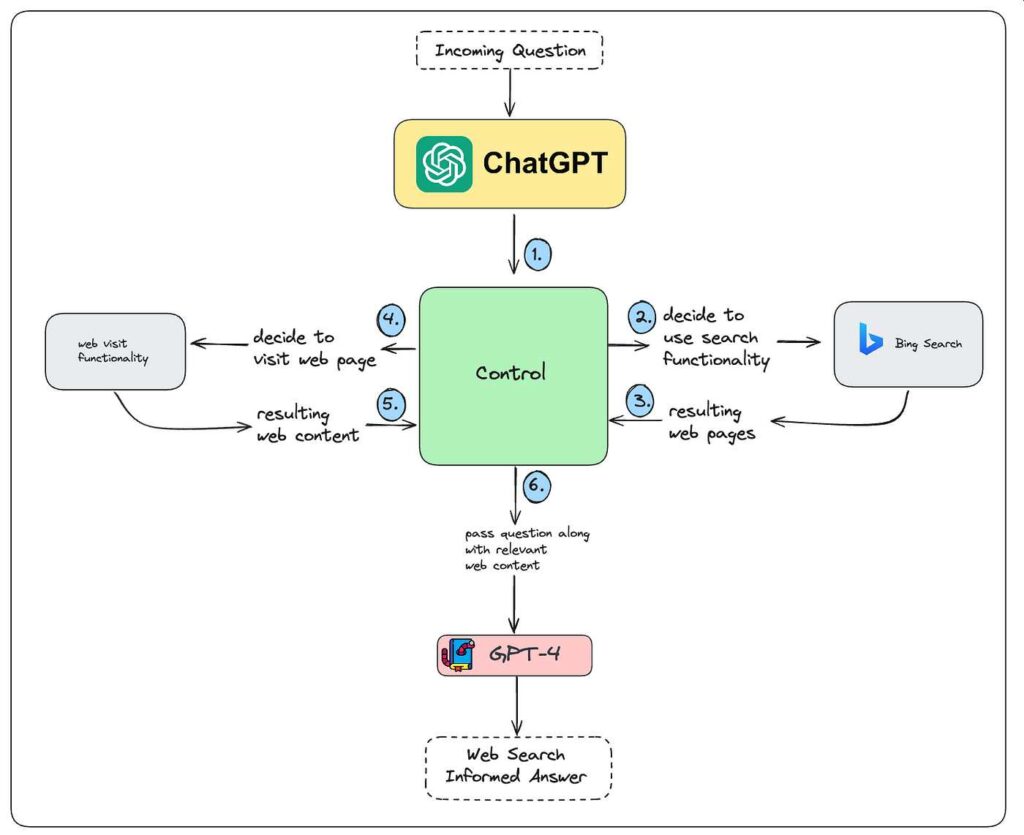
Amikor a ChatGPT-hez hasonló LLM-ek valós idejű válaszokat kínálnak, gyakran keresőmotort használnak háttérként. Például a ChatGPT böngészéssel a Bing Search API-t használja a weben való lekérdezéshez, ahogy azt egy felhasználó tenné. Ezután elolvassa a legjobb néhány találatot, kivonja a releváns tartalmat, és természetes nyelven foglalja össze a választ.
Ez azt jelenti, hogy a hagyományos rangsorolási réteg – a Bing algoritmusa – továbbra is meghatározza, hogy az LLM-ek mely webhelyeket látják először. Ha a tartalom nem oda való, akkor nem valószínű, hogy a mesterséges intelligencia felszínre hozza vagy idézi.
ML6
Speciális API-k: Strukturált adatok valós időben
Például amikor megkérdezi a ChatGPT-t: „Milyen az időjárás jelenleg Tokióban?” nem hallucinál – élő adatokat kér le az OpenWeatherMap-ről vagy egy hasonló API-ról.
Azokban az esetekben, amikor az LLM-eknek pontos, strukturált és gyorsan változó adatokra van szükségük (például részvényárak, időjárás vagy sporteredmények), speciális API-khoz fordulnak. Ezek a következők:
- Pénzügyi API-k, például az Alpha Vantage vagy a Yahoo Finance
- Időjárás API-k, mint például az OpenWeatherMap
- A News API-k, például a NewsAPI.org
- Kripto- és sport API-k
Az LLM nem találja ki és nem generálja ezeket az adatokat – élőben lekérdezi, elemzi az eredményeket, és beilleszti a válaszba.
Retrieval-Augmented Generation (RAG): Privát vagy dinamikus tudás csatlakoztatása
Képzeljen el egy vállalatot, amely egy GPT-alapú asszisztenst használ a belső HR-politikai kérdések megválaszolására. Ahelyett, hogy a nyilvános internetre hagyatkozna, a modell lekérdez egy privát adatbázist vagy egy indexelt dokumentumrendszert, hogy lekérje a legújabb belső szabályzati dokumentumokat.
A nyilvános adatokon túl sok LLM használ RAG-rendszereket a privát vagy frissíthető tudásbázisok lekérdezésére. Ez gyakori a vállalati AI-ban, az ügyfélszolgálati eszközökben vagy a belső mesterségesintelligencia-ügynökökben. A modell először lekéri a releváns kontextust (PDF-ekből, adatbázisokból vagy dokumentumindexekből), majd választ generál mind a betanítása, mind az újonnan lehívott adatok alapján.
Mindent összerakva: Hogyan működik a csővezeték
Íme az egyszerűsített folyamat:
- A felhasználó időérzékeny kérdést tesz fel
- Az LLM keresési/API-lekérdezést generál, és elküldi egy valós idejű forrásnak, például a Bing Search API-nak vagy egy speciális külső API-nak.
- A valós idejű források (Bing, API-k vagy belső dokumentumok) releváns adatokat adnak vissza
- Az LLM elemzi, szűri és szintetizálja a választ
- A felhasználó látja a végső választ, gyakran anélkül, hogy tudná, honnan jött
Miért fontos ez a weboldaltulajdonosok és a tartalomkészítők számára?
Ha azt szeretné, hogy tartalma megjelenjen egy mesterséges intelligencia által generált válaszban, meg kell jelennie az AI által használt forrásokban. Ez azt jelenti:
- Jó helyezés a Bingen (és esetleg a Google-on)
- Világos, nagy megbízhatóságú és a gépek számára könnyen értelmezhető tartalom közzététele
- Adatok strukturálása API-k vagy RAG-rendszerek által használható módon
Röviden: ha a tartalom nem letölthető, akkor felejthető.
A következő lépések: AI feltérképező robotok és közvetlen indexelés
Az OpenAI már elindította a GPTBotot, egy olyan botot, amely webhelyeket látogat meg, hogy esetleg saját indexet készítsen. Ez egy olyan jövőre utal, ahol az LLM-ek kevésbé támaszkodhatnak a Bingre vagy a Google-ra, és inkább saját internetes pillanatképeikre. Ezért nagyon fontos ellenőrizni, hogy a tartalmat miként strukturálják, szolgálják ki és tegyék hozzáférhetővé az AI-rendszerek számára.
Következtetés: Légy látható a mesterséges intelligencia számára, ne csak az emberek számára
Az internet mesterséges intelligencia rétegében nem nyerhet egyszerűen közzététellel. Nyerhetsz, ha visszakereshető, értelmezhető és idézhető adatokat teszel közzé. A láthatóság jövője nem a kulcsszavakon múlik, hanem azon, hogy az LLM-ek a weboldal tulajdonos álltal készített forrást kívánják idézni.
Most, hogy tudja, honnan szerzik be az LLM-ek valós idejű adataikat, a kérdés csak az: megtalálják-e a tiédet?